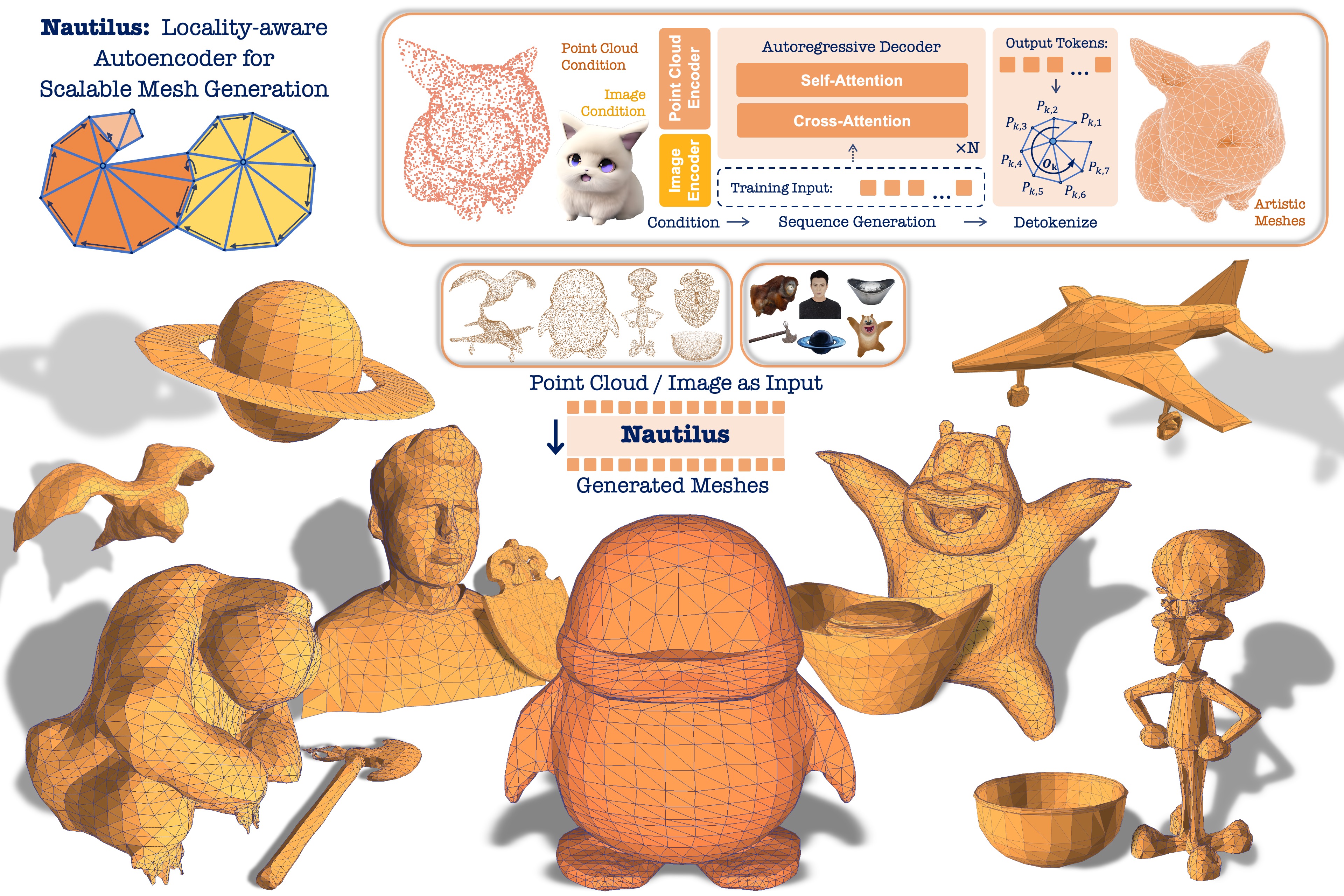
We propose Nautilus, a locality-aware autoregressive autoencoder for artist-like mesh generation. By leveraging the local properties of manifold meshes, it achieves structural fidelity and efficient representation, enabling the generation of meshes with an unprecedented scale of up to 5,000 faces. Extensive experiments demonstrate that Nautilus significantly outperforms state-of-the-art methods in both fidelity and scalability.
Most previous methods employ vanilla tokenization. It processes each face in isolation, simply flattening the three vertices of each triangle face into a 1D sequence.
We introduce a novel Nautilus-style Tokenization that traverses mesh faces in the form of Nautilus shells. Each shell organizes faces around a central vertex O with an ordered sequence of surrounding vertices P. This representation preserves the adjacency of neighboring vertices in sequence and achieves effective compression of sequence length.
Given the input condition, the transformer decoder autoregressively generates the mesh sequences tokenized by the Nautilus-style algorithm. Then in detokenization, the output tokens are converted to interconnected mesh faces, constructing our generated mesh assets. For point cloud condition, we introduce a Dual-stream Point Conditioner to capture global shape information and fine-grained local geometry, ensuring global shape consistency while enhancing local structure fidelity.
Our default input condition for mesh generation is point cloud, given its easy accessibility and rich geometric information. The videos below present the point cloud conditioned generation results of our Nautilus.
Our test conditions are significantly challenging, including thin structures, anisotropic faces, and intricate geometric details, while our Nautilus successfully addresses these challenges and achieves superior quality.
To further expand practical applications, we extend our Nautilus to support image-conditioned mesh generation, where our Nautilus generates detailed, manifold meshes with sharp features that accurately align with the input conditions.
@article{wang2025nautilus,
title={Nautilus: Locality-aware Autoencoder for Scalable Mesh Generation},
author={Wang, Yuxuan and Yi, Xuanyu and Weng, Haohan and Xu, Qingshan and Wei, Xiaokang and Yang, Xianghui and Guo, Chunchao and Chen, Long and Zhang, Hanwang},
journal={arXiv preprint arXiv:2501.14317},
year={2025}
}